

广州实验室自主开发生物医学大数据操作Bio-OS系统
为解决国内生物医学数据密集型科研起步晚、从数据到工具长期受制于国外的问题,广州实验室(以下简称实验室)国家生物数据中心体系粤港澳大湾区节点自主开发了面向生物医学数据科研与产业的原创、开源、开放的生物医学大数据操作系统(以下简称Bio-OS系统)。该系统提供涵盖工作流管理、人机交互、硬件资源管理、数据中台、数据挖掘算子库、AI大模型与知识图谱等智能工具的一站式计算分析环境,连通GA4GH、OPENI等国际主流开源社区,接入56万余全球全基因组数据集,收录了TCGA,GEO,GTEx,HCA,HPA等常用数据库的公开数据集,汇聚10000余个算子镜像、3000余个分析工作流、200余个Workspace、2000余个深度学习算子。
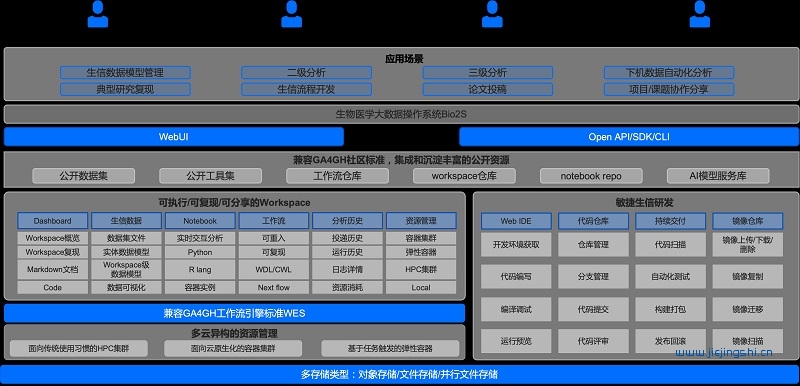

Bio-OS系统对生物医学大数据和信息技术领域的相关先进技术做颠覆性集成创新,将生物医学大数据研究需要的完整干实验环节,包括数据、算法程序、运行环境、计算过程和计算结果封装到基础数据结构Workspace中,Workspace不仅是研究者实施干实验研究过程的实践场所,也是一项生物医学研究工作归档、发表、传播和复现复用的承载单元。Bio-OS系统以Workspace为核心,为每个课题组打造一站式云上生物医学大数据干实验室,通过中心化资源仓库提供丰富的数据集、代码工具、算子镜像、工作流和Workspace,帮助课题组快速展开研究工作。
系统上线运行以来,已支撑50余个科研团队、承接大型项目10个以上,原始数据达到PB级,样本数上万。Bio-OS中心化资源仓库已上线基因组分析(sentieon加速)、转录组分析、单细胞与空间转录组分析、表观遗传学分析、病原与微生物应用、三代测序分析、代谢与蛋白质组等多个方向应用,并持续扩充经典生物信息分析最佳实践。目前系统商业发行版以后端形式部署在中国科学院上海营养与健康研究所,并与十三家科研单位及医院、十余家企业初步达成部署意向;社区开源版已在Github平台公开,并在复旦大学精准医学研究院、深圳先进院完成部署,合作的市场化产品已在售。
Bio-OS系统将底层硬件调度和高效工具开发环境、AI技术融合、大模型驱动、跨平台资源共享、跨领域专家协同等功能进行融合,形成大科学支撑通用技术底座,能够有效整合国内分散的算力算子和数据资源,形成以实验室为中心的分布式跨区域联邦算力协作网络和数据资源网络,可以加速我国生物医学数据密集型科研发展。
